
Genii Weblog
Asking questions to better understand your data
Fri 21 Jul 2017, 03:56 PM
Tweetby Ben Langhinrichs
Most IBM Notes/Domino customers who have used the product for a number of years have vast stores of data, but when they want to try to glean new insights, they are stymied by how to handle the data mining. Simple fields which map well to views are easy to extract, and are often relatively "clean", meaning that the value is what the value says it should be. But real applications, especially those built for internal use, often reflect a far more complex set of relationships. They may use parent-child hierarchies, doclinks, lookups to other databases. They may also contain information stored in multi-value fields or rich text fields that require manipulation and cleanup.
While there are a number of techniques available from DXL to data scraping, it can quickly become programming intensive to find information and put it together. With this in mind, we have built a fairly easy database using the Midas LSX engine to extract, correlate and prepare data from different sources and build a result which does not always have a one-to-one correspondence with Notes documents. The main virtue of this approach is the ease with which you can ask questions and put together sources. If you decide you have something wrong or need something else, it takes just a minute to remove or add it.
I wanted to show how this works with an existing application used over a period of years by fairly sophisticated Notes users. I chose as a source the IBM Business Partner forums, because they are widely available and familiar. One of the different uses for these forums over several years was to allow partners to file Possible Bug reports, which IBMers could monitor and use to create SPRs and so forth. In this brief video, I pose five questions of this fairly simple application. Imagine how you could use a similar application to delve into your company's data.
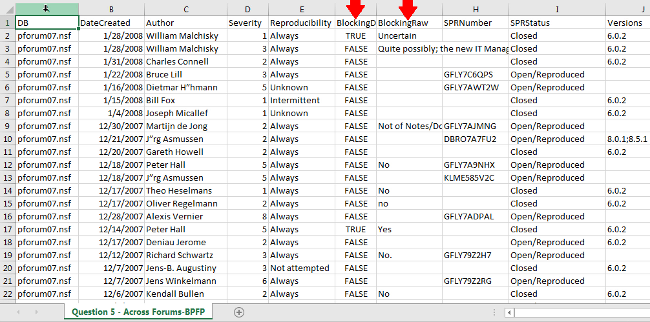
Note that I don't talk much in the video about data cleaning, but if you look at the image below, note that the column F (first red arrow) is derived automatically by Midas as a boolean from column G (second red arrow). We have some data cleaning built in as options, but are also looking at ways to provide custom data cleaning and normalization for individual items. While it is inevitable that some data cleaning will be done after the data is loaded into data analysis or data visualization software, the cleaner it can be the better, as 80% of all time doing data analytics is preparing and cleaning and normalization the data. We are eager to discuss with customers how we can minimize that costly effort.
Copyright © 2017 Genii Software Ltd.
What has been said: